NVIDIA GPU & Proxmox

If you've wondered ever why is it easy to create abstractions like Virtual CPU, RAM, Disk, but not GPU and get equivalent performance? Indeed I did. Why is it that for GPUs the standard tutorials suggested to simply pass through the entire GPU (using PCIe Passthrough) or simply add virtual GPU.
Indeed if you'll go down this rabbit hole, you'll find that there have been efforts since quite some time, but they were mainly used and hence maintained for Datacenter products like NVIDIA Quadro, Ps, As etc. For Intel, they did support this in thier chip and it works to quite some extent, but I needed this to work for NVIDIA which they don't support for consumer graphic cards. Another thing about virtualization is the hard boundaries that the resources have, and thus dynamic sharing is not possible.
Which lead me to think around that into LXC containers. I love LXC containers since they behave like VMs in almost no sense except the image management, and they are as lightweight as a container. And this actually works well with NVIDIA as well!
I started with a great post that basically explained how to go about it. The only modification that I had to do was that I didnt have any nvidiactl in /dev/nvidia thus the resultant looked a bit different like below.
lxc.cgroup2.devices.allow: c 195:* rwm
lxc.cgroup2.devices.allow: c 510:* rwm
lxc.cgroup2.devices.allow: c 235:* rwm
lxc.mount.entry: /dev/nvidia0 dev/nvidia0 none bind,optional,create=file
lxc.mount.entry: /dev/nvidiactl dev/nvidiactl none bind,optional,create=file
lxc.mount.entry: /dev/nvidia-uvm dev/nvidia-uvm none bind,optional,create=file
lxc.mount.entry: /dev/nvidia-modeset dev/nvidia-modeset none bind,optional,create=file
lxc.mount.entry: /dev/nvidia-uvm-tools dev/nvidia-uvm-tools none bind,optional,create=file
lxc.mount.entry: /dev/nvidia-caps/nvidia-cap1 dev/nvidia-caps/nvidia-cap1 none bind,optional,create=file
lxc.mount.entry: /dev/nvidia-caps/nvidia-cap2 dev/nvidia-caps/nvidia-cap2 none bind,optional,create=file
Using the tutorial I was able to run DL toolkits (both Tensorflow and PyTorch) along with some benchmarks like HashCat. Since these are containers, performance is native with slight overheads, but overall it also allows sharing the container between the GPUs.
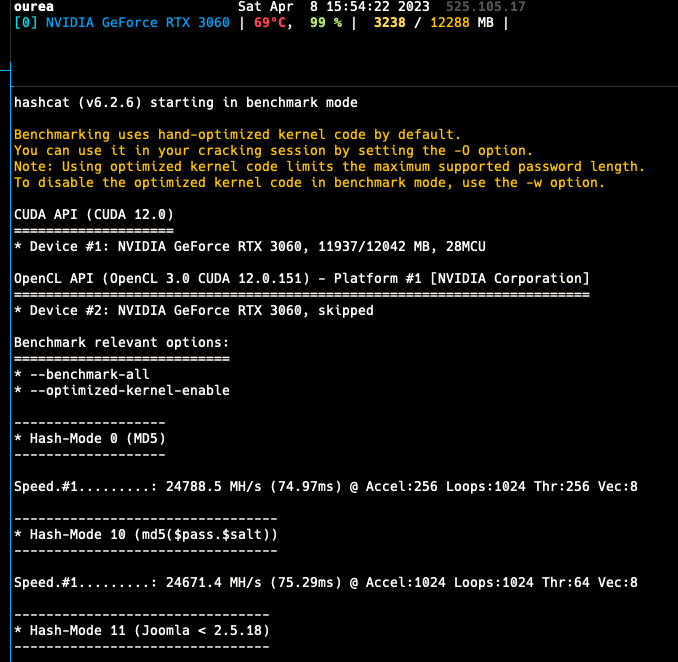
The pitfall is that the containers need to play-nice with each other, since if one container is simply hogging the GPU memory by loading the model, but not doing any training or inference, other containers may find the memory limiting. However in my experience, using RTX 3060 which has 12 GB VRAM, along with mixed precision, I could easily fill my VRAM with multiple small models or even a single large model.
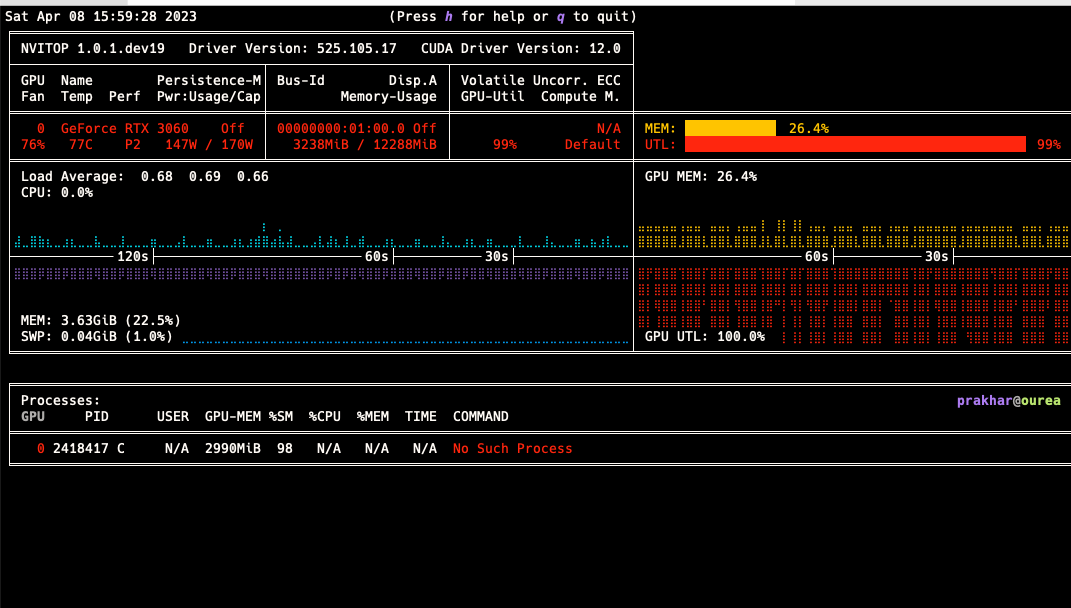
I did the above as a simple usecase of where I needed a abstracted reusable environment, like a VM, so that someone can SSH into it, do thier work, have backups enabled for it, and in case things go south, restore those backup via a web GUI. This is not easily possible running things natively and DL projects are notorious for thier dependencies and conflicts, and thus this seemed to me the best approach for this particular problem. Hope this helps you out in the future.