Why I love OpenZFS
First of all, let me clarify that this post uses OpenZFS, but the technology marvel that it is is based on ZFS, which is something that I truly appreciate. However the original implementation of ZFS was built for BSD Solaris with some license concerns, but OpenZFS clearly integrated with Linux and is not under a restrictive license.
If you've worked with any RAID systems, you will understand that RAID is there to take care of hardware faults when disks fail and also to enhance the performance possible beyond that of a single disk. For example, you may use a RAID 0 to combine the 2 disks to behave as 1 giant faster disk (for simplicity let's assume this is always true, although it is not). You may also use a RAID 1, to allow disk redundancy, to tolerate failure of a member disk. You may also combine the two, into RAID 10.
And this seems like a perfect system combined with file systems, like EXT4 has built in journal (which you can disable or enable as per your requirements) to get further reliability, such as in case of a power failure. You may also use some advanced file systems like BTRFS, to have Copy-on-Write, thus ensuring atomic writes to the maximum. There is are so many optimization here, that it is out of scope for this post.
However there is one basic tenet that is an issue. Sometime disks can report they're fine when they're not! For example, data might be corrupted, but they'll think it is not. This will sometime slip through the lower layers as well. However, ZFS does not trust the hardware itself. It assumes the worst and every once in a while verifies the content in the background itself. And while you might think this does not happen often (maybe it wont with enterprise hardware as easily) but I've commodity hardware based local cluster, which encountered this within first year. I was using OpenZFS with raidz1
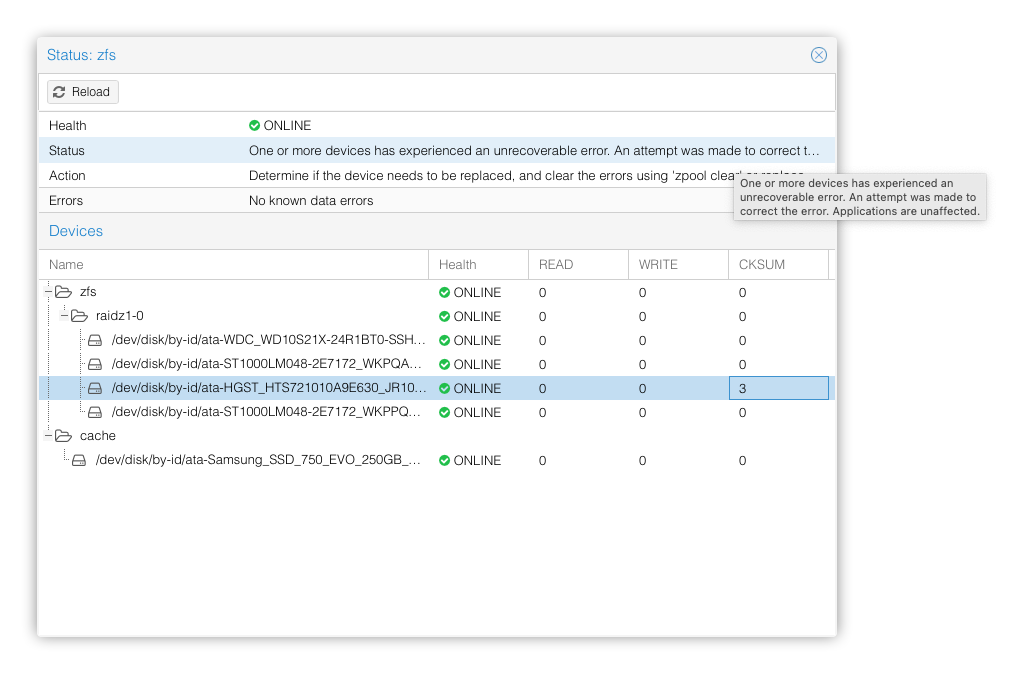
And as expected this disk failed eventually as we can see below.
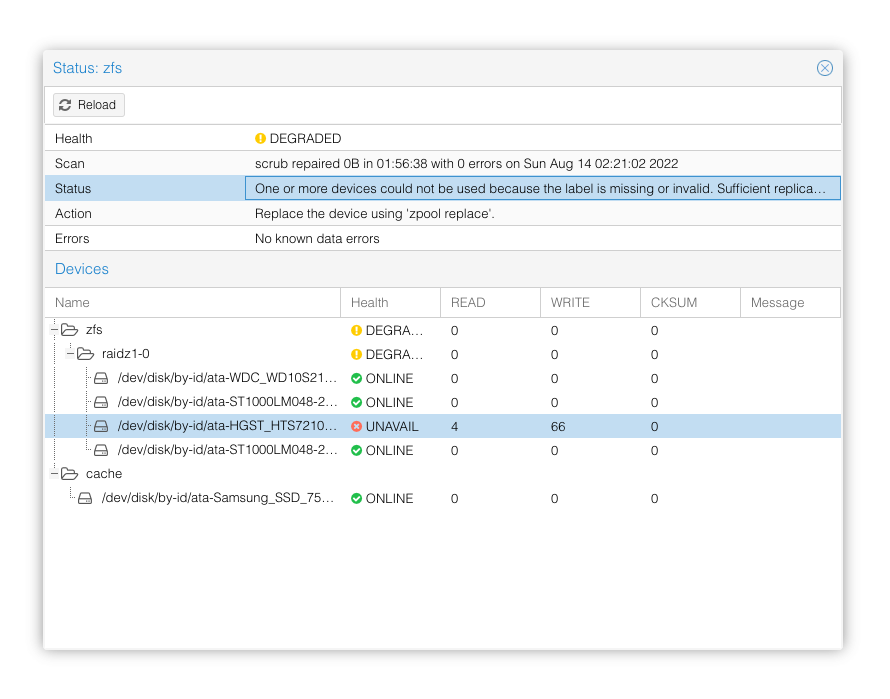
And then I added a new disk with a few simple commands, to get the resilvering started. Resilvering with ZFS is much faster than MDADM or Hardware RAID solutions, since only the actual allocated blocks are resilvered, and rest are simply ignored.
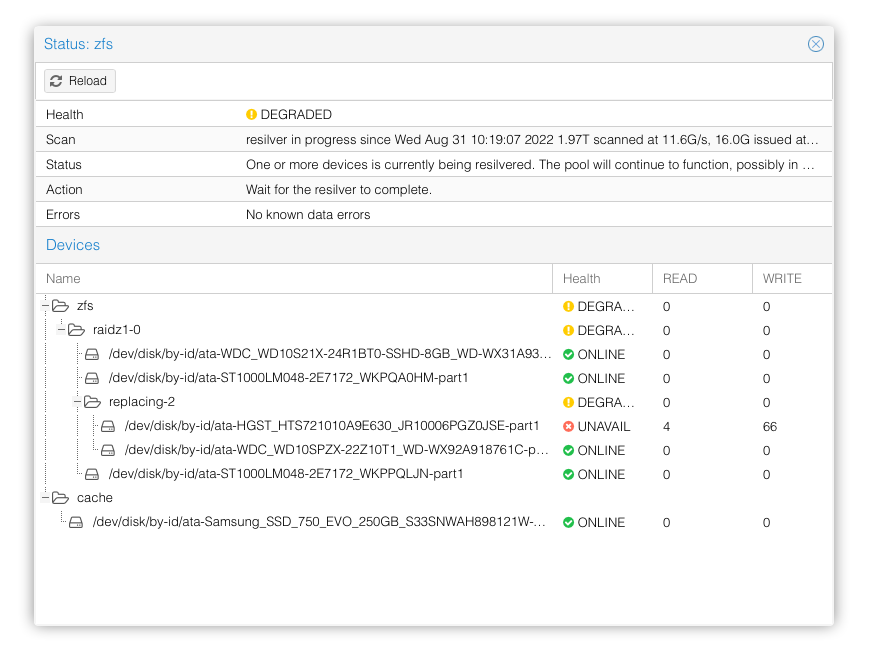
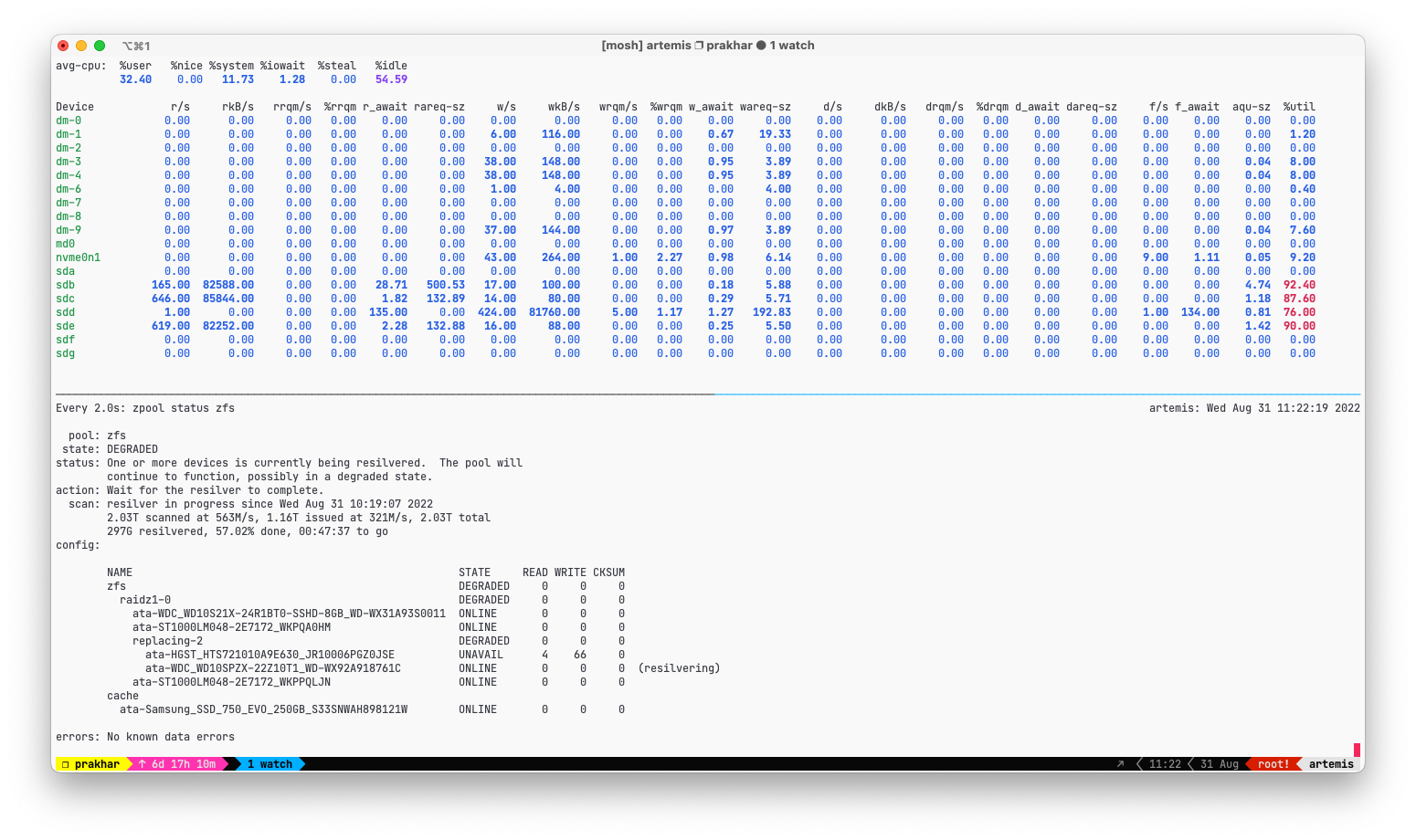
And after completion the cluster went back to normal.
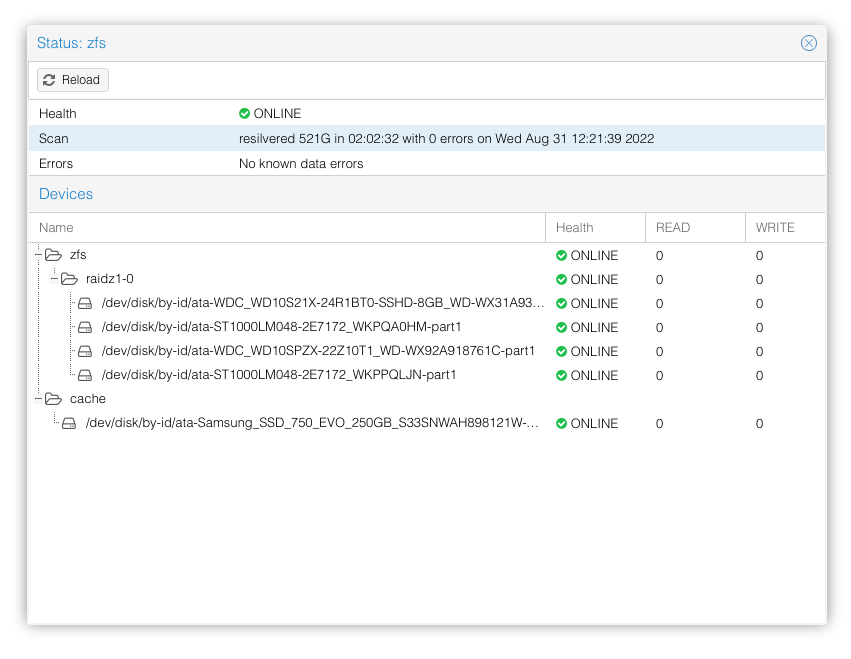
And all this seamlessly worked while data was online. And while RAID5 would have worked similarly, the performance of resilvering and detection of the issue was very bad, to the point that sometimes old disks would fail to detect corruption and raise that as a SMART error, which would then lead to system believing that everything was fine.
Lastly I'd like to add that I also used bcache as an SSD cache over my mdadm RAID 5 setup for read caching, and when a device has to be detached to the bcache, the process is lengthy and quirksome to say the least. Here again, OpenZFS allows us simply attach and detach (and infact work seamlessly) even if the caching device fails.
I dont have a ZIL device, and instead rely on L2ARC which tries to cache reads and not help with write. ZIL is better suited for devices with high write performance and endurance, and since I used commodity hardware endurance was a concern. But I did use enterprise SSD or Optane drives, I would definitely enable that.